收录整理
Google TurboQuant:把AI记忆成本砍掉6倍、速度提升8倍的新算法
这篇文章用通俗语言解释了TurboQuant的核心创新:极坐标量化(PolarQuant)和1位残差压缩(QJL)的组合,如何在不损失精度的情况下实现超大幅度内存压缩。
Reading System
这篇文章用通俗语言解释了TurboQuant的核心创新:极坐标量化(PolarQuant)和1位残差压缩(QJL)的组合,如何在不损失精度的情况下实现超大幅度内存压缩。
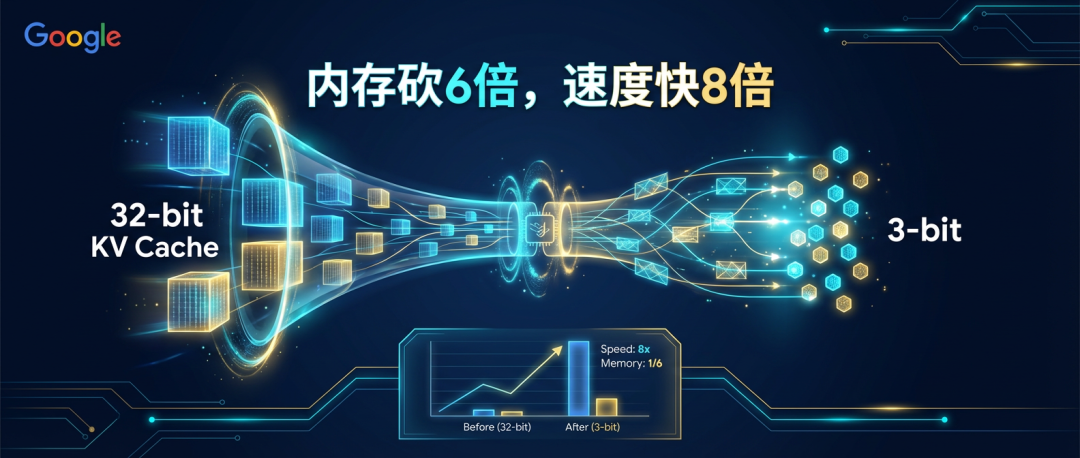
导读: Google 发布了一个叫 TurboQuant 的算法,把 AI 的"记忆成本"砍掉了 6 倍,速度还快了 8 倍。更离谱的是:精度没有任何损失,也不需要重新训练模型。这篇文章用你能听懂的话,把这件事讲清楚。
你有没有注意到,用 AI 处理很长的文章时,它会越来越慢,甚至直接报错"上下文太长"?
这不是 AI 在偷懒,是它遇到了一个真实的瓶颈。
AI 模型在生成每个字的时候,都需要"回头看"前面所有的内容,判断接下来说什么。这个"回头看"的过程,依赖一个叫 KV cache(键值缓存) 的东西。
用一个生活类比来说:
KV cache 就像你做笔记。你在读一本书,每读一段就把重点记在便利贴上,这样回头查的时候不用重新翻书。AI 处理每个词,就往这个"便利贴本"里加一张纸。
问题是,文章越长,便利贴越多,内存越撑越爆。
一个处理 10 万字长文的 AI,它的 KV cache 可能要占掉整个 GPU 内存的大半。这直接导致:
既然 KV cache 占内存,那把它压缩不就行了?
方向是对的。压缩方法叫向量量化——将每个数据从"高精度小数"(比如 32 位浮点数)换成"低精度整数"(比如 4 位整数)。就像把精确到毫米的尺子换成只精确到厘米的,存储空间小多了。
但传统方法有个隐藏成本:
每次量化,都要存一份"翻译说明书"。 就像把"3.14159"缩写成"3",事后要知道这个"3"代表多少,你需要一份附注说明每块数据是怎么压缩的。这份说明本身也要占内存,每个数还要额外付出 1-2 bit 的管理开销。
压缩了,但开销抵消掉了一大半收益。
这就是 TurboQuant 要解决的核心问题:能不能量化,但不存这份"说明书"?

TurboQuant 的答案分两步,都挺有意思。
普通量化是在"直角坐标系"里做的:把一个点用 X、Y、Z 三个轴上的距离来描述,每个轴都需要单独做量化。边界不固定,所以需要存一份说明书。
PolarQuant 换了一种描述方式——极坐标。
用人话说就是:
与其说"往东走 3 步、再往北走 4 步",不如说"往 37 度方向走 5 步"。两种说法到的地方一样,但第二种更紧凑。
切换到极坐标之后,有一个关键特性:角度的分布规律是固定的、可预测的。因为规律已知,模型不需要再为每块数据单独计算和存储边界参数。那本"翻译说明书"消失了。
PolarQuant 压完之后,还会有一丁点误差留下来。
QJL(量化 Johnson-Lindenstrauss 变换)用一个数学技巧,把这个残差误差压缩成一个 符号位(+1 或 -1)——1 bit,而且不需要额外存储空间。
更关键的是,它能消除系统性偏差。量化本身会让模型的注意力分数产生微小但稳定的偏差,QJL 就是把这个偏差修正掉。
两步加起来:KV cache 压到 3 bit,内存减少 6 倍以上,速度快 8 倍,精度几乎不变。

Google 用 Gemma 和 Mistral 两个开源模型,在五个长上下文基准上做了测试:
| 测试集 | 考察什么 | |---|---| | LongBench | 综合长文理解 | | Needle In A Haystack | 在海量文本里找一条具体信息 | | ZeroSCROLLS | 长文摘要和问答 | | RULER | 复杂长上下文推理 | | L-Eval | 多维度长文评估 |
论文报告的主要指标:
| 指标 | TurboQuant | 原始基线 | |---|---|---| | KV cache 位宽 | 3–4 bit | 32 bit | | 内存占用 | 减少 6x 以上 | — | | 注意力计算速度(H100) | 提升 8x | 32-bit 无量化 | | 精度损失 | 几乎为零 | full precision | | 需要重新训练 | 否 | — |
"Needle In A Haystack"测试是最极端的场景之一:在几十万字的文本里藏一句话,看 AI 能不能找到。这对 KV cache 的质量要求极高。TurboQuant 在这类测试上几乎和不压缩时的表现一样。
这件事本身说明了 TurboQuant 的实现难度——不高。
开发者 @nostponsnek 在论文出来的当晚就开始动手,在 llama.cpp 上(本地跑 AI 最流行的框架)实现 TurboQuant。36 小时后,他发推:能跑了,而且比原来更快。
他公开记录的数据:
| 指标 | 数值 | |---|---| | KV cache 压缩比 | 4.6x | | 速度 vs 原量化基线(q80) | +2%(更快!) | | 精度偏差(PPL) | +1.3% | | 从零实现到可用 | 36 小时 |
为什么压缩了反而更快?因为 cache 变小了,GPU 搬运数据的时间也少了。内存带宽才是 AI 推理的真正瓶颈之一,cache 越小,读写越快。
他还记录了整个优化过程:Token/s 从 739 → 1074 → 1411 → 2095 → 2747,每一步都有明确的优化点。关键一跳是把旋转操作移到"计算图侧",相当于把一个每次都要临时做的计算提前做好放在那里。

TurboQuant 博客一发,美光(MU)跌 5.8%,SanDisk 跌 8.3%。
市场的逻辑很直接:AI 推理少用内存 → 买 HBM 内存芯片的需求减少 → 内存厂商受损。
但分析师 Valentinus Capital 指出了一件有意思的事:TurboQuant 的论文其实是 2025 年 4 月就挂在 arXiv 上的,Google 只是现在写博客宣传。论文在学界存在了将近一年,市场在博客发出后才动。
他还提出了另一个反驳逻辑:杰文斯悖论——每次计算变便宜,人们反而会用得更多,总需求不降反升。历史上,存储更便宜 → 存的东西更多;带宽更高 → 发的视频更大。算力也是同理。
这个判断对不对,现在还说不准。但"技术效率提升 → 需求减少"这个推断,历史胜率其实不高。

AI 提速 8 倍、省内存 6 倍,数字够吓人了。但 TurboQuant 真正值得关注的地方在于:它有数学证明。
不是调参调出来的经验结果,是在信息论层面可以证明的近似最优解。这意味着:
Google 博客里提到,这个思路也适用于搜索引擎的向量索引。现代搜索要在数十亿个向量里做相似度查找,TurboQuant 能让索引更小、查询更快。Gemini 系统是潜在的应用场景之一。
工程落地还需要时间。llama.cpp 的社区实现是个好信号,但生产级部署在不同推理框架、不同硬件上的适配成本,论文里还没讲清楚。这件事值得继续跟进。